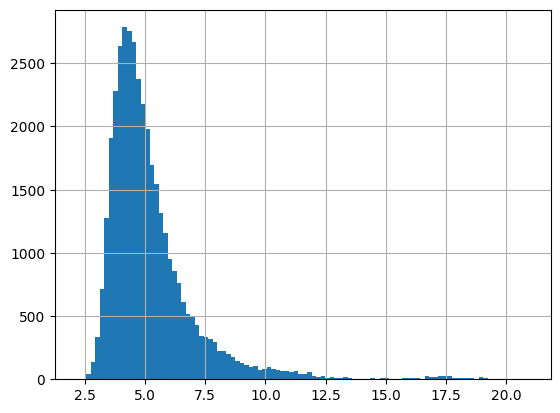
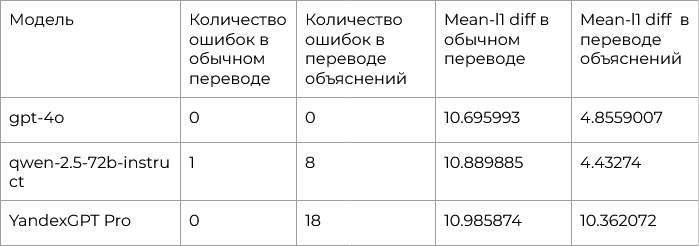
Изначально пост был размещен на Хабре в блоге MWS AI. На правах авторов, дублируем его в нашем блоге.
Привет, Хабр! В этом посте речь пойдет о специфическом датасете, предназначенном для решения очень важной задачи — разработки ML-инструмента, помогающего своевременно выявлять предпосылки и предотвращать суициды. Мы с командой «Пситехлаб», специализирующейся на ИИ-решениях для психотерапии, собирали его по вечерам. Этот проект диссертационный, он не входит в мои обязанности в рамках работы в MWS AI, но опыт, приобретенный в компании, стал базой, без которой его бы не было.
Мы написали научную статью по созданию этого датасета. Если будете использовать наш датасет, пожалуйста, процитируйте.
Давайте начнем с контекста. Почему этот проект так важен
По данным ВОЗ, мир ежегодно теряет более 700 тысяч человек вследствие суицида. Представьте, целый город, причем не маленький, исчезает каждый год. По России свежую статистику мне пока не удалось найти, но вот в 2019-м было 17 тысяч случаев самоубийств, в 2022-м — 13,5 тысяч (это данные Росстата). Хорошая новость в том, что количество таких трагедий у нас сокращается год от года: с момента пика, который пришелся на 1994 год и составил рекордные 61,8 тысяч случаев, — падение почти в шесть раз! Но мы очень хотим, чтобы это число падало еще быстрее. И вообще, чтобы оно было нулевым.
На это и направлена наша инициатива. Мы хотим помочь вовремя оказывать поддержку людям, находящимся на грани. Существуют специализированные НКО, которые ищут таких людей в социальных сетях и помогают им в пределах своих прав и возможностей, а также сотрудничая с МВД и ФСБ. А задача команды «Пситехлаб» — облегчить этот поиск.
Как это происходит
В социальной сети есть обычные пользователи, чьи тексты чаще всего нерелевантны для нашей темы. А есть те, кто проявляет признаки склонности к самоубийству, — наша целевая аудитория. Также есть боты, фейки и люди, которые не подают явных признаков, и мы пока не умеем с ними работать.
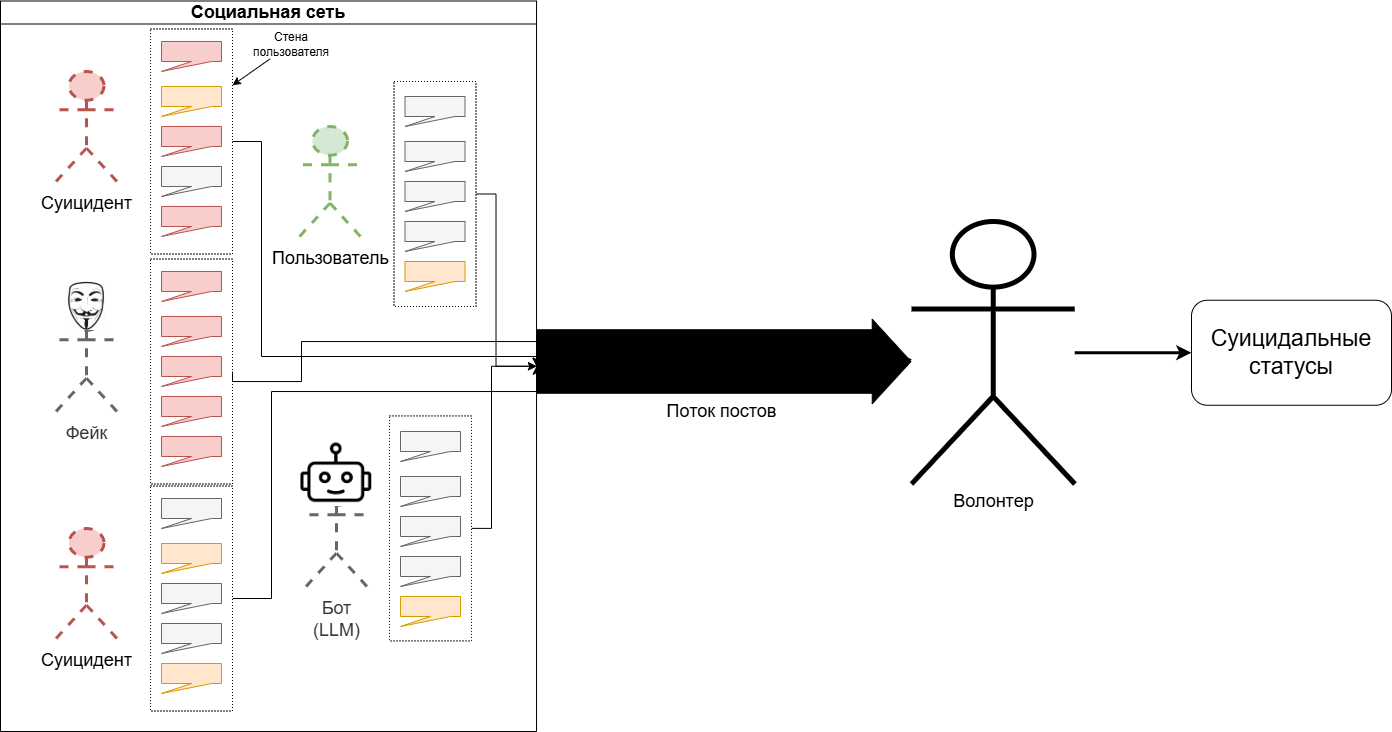
Все посты в социальных сетях анализируются волонтерами из НКО: на основании постов они присваивают пользователям так называемые суицидальные статусы. Важно отметить, что суицидальный статус — это не диагноз, а такой маркер, указывающий, нужно ли обращать внимание на конкретный аккаунт. Если статус высокий, то это повод поискать дополнительную информацию о пользователе, выяснить, человек ли это вообще, возможно, принять какие-то меры.
Проблема заключается в том, что приходится анализировать огромное количество текстов. По собранной нами статистике, на 100 постов приходится только 20 таких, которые содержат целевую информацию, — это различные негативные ситуации, выражения эмоций, призывы о помощи и так далее.
Волонтерский ML
Мы предлагаем систему, которая будет помогать фильтровать нерелевантные посты, тем самым снижая нагрузку на волонтеров и увеличивая их КПД. Для этого мы собираем датасет, чтобы построить модель машинного обучения, которая будет выполнять эту задачу. Причем цель у нас довольно амбициозная: собрать 50 тысяч размеченных текстов. Это больше, чем любой другой датасет по смежной теме даже на английском языке.
Важный дисклеймер: каждый раз, когда я рассказываю про свой проект, почему-то возникает впечатление, будто мы строим модель, предсказывающую именно суицид, что не так. Поэтому регулярно слышу вопрос «У вас психологи размечали?». Нет, не психологи. Мы лишь определяем тексты, которые описывают определенные факторы (пример я приводил чуть выше). Чтобы определить, что человек пишет, что ему плохо или что он пережил насилие или травлю, не нужно быть психологом. Достаточно просто иметь здравый смысл. Наша идея в том, чтобы волонтером мог стать каждый человек. Со всем этим дисклеймером и контекстом давайте перейдем непосредственно к сборке датасета.
Как мы собирали датасет
Мы использовали открытые источники — например, существующие датасеты, а также (внезапно) олдскульные форумы нулевых годов, где люди обсуждали тему самоубийства. Там люди часто делились своими историями и иногда получали психологическую поддержку. В их постах чуть ли не в каждом предложении можно было встретить какой-то суицидальный фактор. И таких историй сотни.
После сбора данных мы обогащали их различными признаками: наличие и тип местоимений, указания на родственные связи, количество слов, эмоции, сентимент и так далее. С помощью этих признаков можно отбирать тексты на разметку так, чтобы нужные классы появлялись с большей вероятностью. Мы применяли как различные эвристики, так и существующие открытые модели. Мы очень благодарны разработчикам, которые выложили их в открытый доступ, — это очень ценно.
Из интересного: обычная модель сентимента, которая предсказывает нейтральный, негативный или позитивный сентимент, тексты с суицидальными мыслями определяла как нейтральные. Например, фраза «я хочу умереть» оценивалась как нейтральная. Для антисуицидальной части датасета, о которой я расскажу чуть позже, нам очень помогла модель эмоций. Это логично, ведь антисуицидальные тексты, как даже из названия можно догадаться, часто связаны с такими эмоциями, как радость (Joy) или удивление (Surprise). Итак, мы собрали и обогатили данные. Теперь перейдем к сердцу любого датасета — инструкции.
Инструкция
Наша инструкция состоит всего из двух частей: основной части и таблицы классов. В основной части стандартно описывалось, что, зачем и как размечать. Также там были прописаны разные принципы разметки. Внимательно посмотрим на два самых важных принципа:
- Содержание текста должно относиться к автору. Мы хотим предсказывать только то, что относится к автору текста, а не то, что относится к третьему лицу. Пример:
- Я хочу сбежать из этого давящего внешнего мира к себе внутрь.
- У меня нет сил это терпеть.
- У него такая жесть дома происходит.
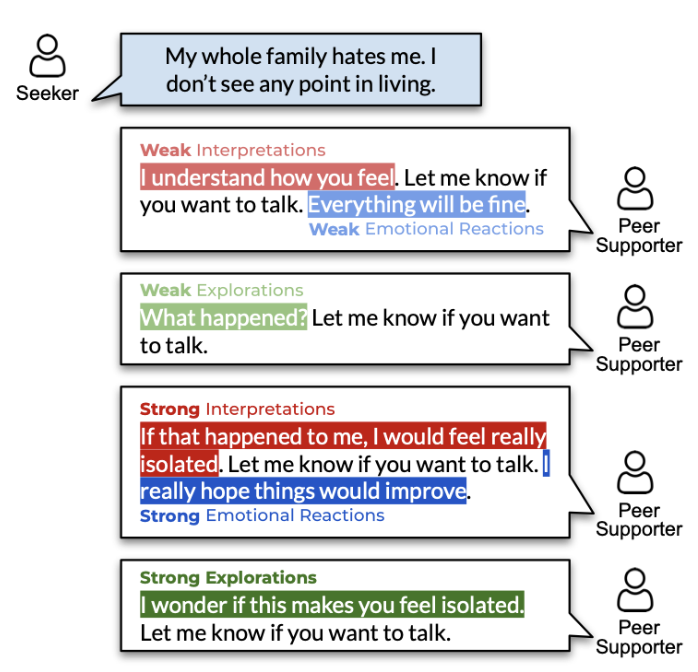
- Не допускать необоснованных интерпретаций. Это проще показать на примере. Прочитайте текст и скажите, какую сцену он описывает.
«Я ненадолго отошел, а когда вернулся, она успела прочитать всю нашу откровенную переписку».
Многие подумают, что жена или девушка прочитала переписку партнера с любовницей с ожидаемым исходом. По нашей инструкции это можно интерпретировать как пресуицидальный сигнал: отношения, которые, не заладились и сломались. Однако это неверно, потому что вы додумали контекст. Из этого текста напрямую не следует, что отношения развалились. Строго говоря, даже не следует, что это любовные отношения. А что, если тут речь идет о маме, которая прочитала переписку сына-подростка? Скорее всего, предыдущее или следующее предложение как раз содержит полную информацию.
Теперь коснемся таблицы классов. Точнее, как мы ее создавали. Глобальная цель — разметить тексты на три большие группы сигналов:
- Пресуицидальные сигналы: факторы, склоняющие к суициду.
- Антисуицидальные сигналы: факторы, условно сберегающие.
- Нерелевантные сигналы: большая часть текстов, которые нам неинтересны и которые мы хотим исключить из рассмотрения.
Мы нашли несколько существующих систем классов, разложили их и объединили так, чтобы новые классы удовлетворяли двум условиям:
- Атомарность — фактор нельзя «разбить» на составляющие.
- Семантическая независимость — тексты разных классов должны как можно меньше пересекаться по смыслу.
Это сделано для того, чтобы любой человек, работавший в какой-то одной из систем, мог адаптировать нашу систему под себя.

На картинке выше показан пример того, как мы анализировали существующие системы классов. Я называю эту технику «Доска настроений». Мы просто выписываем все таблички с факторами и маркируем их одинаковым цветом, если считаем, что они похожи. Затем пытаемся их объединить: какие-то выбрасываем, какие-то добавляем.
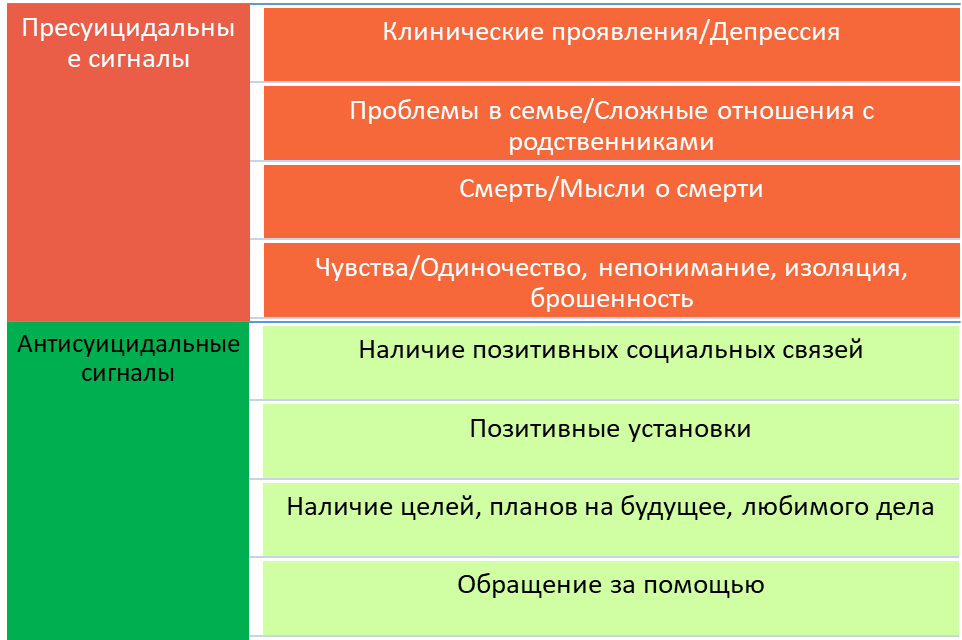
Вот пример сигналов, которые мы выделили: красный — пресуицидальный, зеленый — антисуицидальный. Всего у нас получилось 33 пресуицидальных класса, объединенных в семь групп, и 12 антисуицидальных классов без деления на группы.
Тестовая разметка
После того как собрали базовую сетку классов, решили провести тестовую разметку собственными силами. Ее схема состояла из двух кругов:
- Первый круг выполняли я и моя коллега, участвовавшие в сборе датасета изначально.
- Второй круг выполняли члены нашей команды, которые никогда не видели данных и ранее не имели отношения к нашей теме. Это было сделано для того, чтобы смоделировать ситуацию, когда только что пришедший волонтер вливается в процесс.
Что мы выявили в результате тестовой разметки?
Во-первых, мы обнаружили, что наши тексты часто содержат несколько классов. Это multi-label. Из этого напрямую возникают некоторые технические вопросы:
- Как объединять разметку, если один текст размечен более чем одним человеком?
- Как считать степень согласия?
Первую проблему мы решили мягким голосованием большинством. Составляем единый список из всех классов, которые поставили люди, и из него выбираем те, что встретились больше, чем n раз. На нашей тестовой разметке такой подход дал хорошие показатели по покрытию — количеству текстов, которые имеют хотя бы один класс, и итоговому качеству меток. У простого голосования большинством слишком много примеров просто не получали никакой метки.
Вторую проблему решили с помощью альфы Криппендорфа и специальной метрики MASI (Measuring agreement of set-valued items), которая используется в качестве ядра. Эта метрика на самом деле представляет собой метрику Жаккара со специальным коэффициентом. Из коробки ее можно посчитать с помощью — барабанная дробь — NLTK.
Еще одна особенность наших данных — это субъективность. Когда мы на этапе обратной связи разговаривали с членами команды, мы не всегда могли оспорить их выбор класса. То есть они ставили какой-то класс, мы считали, что он неправильный, спрашивали «почему?», они отвечали, и мы как будто бы соглашались, что «вроде окей». Это делает нашу задачу очень близкой к сентименту и к эмоциям. Несмотря на то, что классы прописаны довольно хорошо, жизненный опыт все равно играет большую роль. Кто-то спросит, а почему мы не указывали такие примеры как частные случаи (корнер-кейсы)? Проблема в том, что таких текстов было много и мы с коллегой просто бы не вывезли следить за длинным непротиворечивым списком таких случаев.
Где искали разметчиков
Мы написали инструкцию, подготовили данные и хотим начать размечать. Для разметки обычно у нас есть два пути: краудсорсинг и индивидуальные разметчики. У каждого есть свои плюсы и минусы, которые указаны на картинке ниже. Мы изначально думали использовать краудсорсинг, так как это дешевле и быстрее, плюс у нас был опыт работы с Яндекс.Толокой — самой известной до недавнего времени платформой для краудсорсинга.

Проблема в том, что Яндекс.Толока ушла в начале 2024 года, вместо нее появились Яндекс.Задания. Казалось бы, что могло пойти не так? А пошло не так то, что эта платформа не работает с физическими лицами: вы не можете быть заказчиком так просто — вам обязательно нужно юридическое лицо. Мы потратили очень много времени на то, чтобы такое юрлицо организовать.
Это шло параллельно тестовой разметке, и когда мы ее закончили, поняли, что субъективность, помноженная на низкую мотивированность в краудсорсинге, ни к чему хорошему не приведет. Поэтому решили действовать с помощью индивидуальных разметчиков. Тем более я сам два года отработал в разметке в MWS AI, где налаживал автоматизацию процессов.
Среди всех платформ, где мы искали разметчиков, нас очень удивил Фриланс.ру, где мы собрали целых 30 откликов. Пришлось даже выбирать по сопроводительным письмам. Мы выстроили процесс найма таким образом, чтобы даже люди без опыта в разметке могли научиться и минимизировать ошибки в результате. В целом, как видно, нам это удалось: 27% ошибок в начале, конечно, много, но 4,6% в конце процесса — это уже приемлемо.
Интересный момент: во время проверки тестовых заданий разметчиков мы чаще всего сталкивались как раз с ошибками, связанными с нарушением тех двух принципов, о которых я говорил: отношение содержания текста к автору и недопустимость интерпретаций. Еще занятный факт: почему-то текст, где было рассуждение типа «А если я не отдохну, то превращаюсь в ходящее зомби», все восемь человек посчитали как свершившийся факт и поставили соответствующий класс.
Наш полный процесс разметки в целом ничем не отличается от любого другого, кроме того, что у нас есть сбор обратной связи и психологическое вентилирование. Чуть позже я расскажу об этом подробнее. А сейчас немного про инструменты.
Какие инструменты использовали
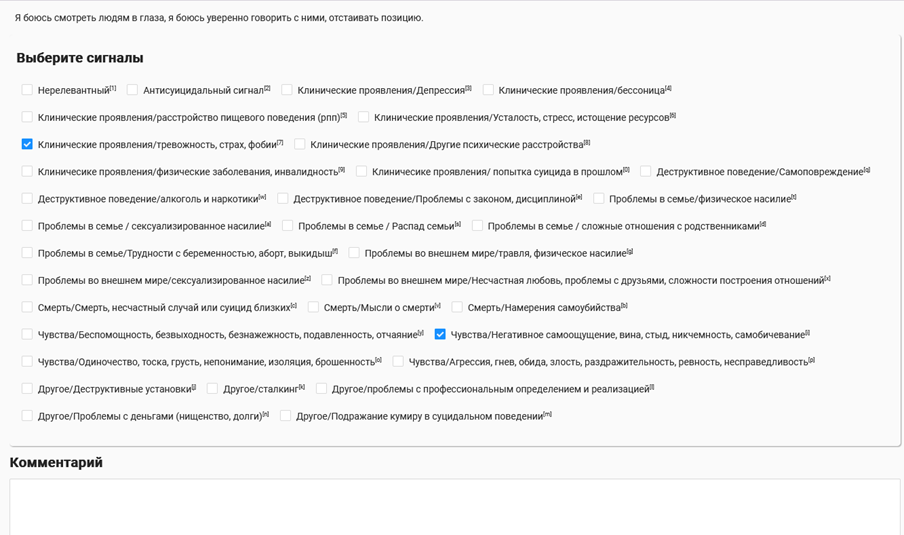
Мы размечали данные в Label Studio. Это очень хорошая платформа, ключевая особенность которой в том, что она позволяет создать интерфейс почти под любые задачи. Я пока не встречал задач, для которой бы у меня не получилось создать интерфейс. Плюс у меня большой опыт работы с ней. Вот так выглядит интерфейс разметки, который мы использовали.
Следующий важный вопрос: где мы хранили данные? Мы использовали ClearML. Если вы никогда не сталкивались с потерей данных или путаницей в версиях, то и хорошо. Чтобы и впредь не сталкиваться, используйте ClearML или аналогичные платформы, которые позволяют версионировать датасеты. Поверьте, это очень важный аспект.
Забота о разметчиках
Как вы знаете или, по крайней мере, догадываетесь, разметчики работали не с контентом про кошечек и собачек, а с эмоционально тяжелыми текстами. Мы опасались, что это может как-то повлиять на их психологическое состояние. Поэтому контролировали наших разметчиков как инструментально (при помощи тестов), так и через вентилирования. Это формат интервью, когда мы выстраиваем безопасные, доверительные отношения и проговариваем вещи, которые могли случиться с разметчиками, пока они что-то размечали.
В ходе этих интервью выявили несколько интересных моментов. Во-первых, у некоторых разметчиков действительно была реакция на ряд текстов в начале работы, но к середине у всех получилось дистанцироваться от того, что они читают. Более того, кому-то в конце уже даже эти интервью не понадобились. Во-вторых, было приятно узнать, что как сайд-эффект от работы несколько разметчиков получили более глубокое понимание своих детей-подростков.
Как мы верифицировали и исправляли датасет
Прежде чем говорить о качестве нашего датасета, вспомним, что мы хотим разметить 50 тысяч примеров. Это очень много. Чтобы замеры качества были адекватными, тестовую часть датасета мы размечали с перекрытием, то есть несколько человек размечают один и тот же пример, а итоговый результат получается с помощью агрегации отдельных разметок. Размечать так датасет полностью, к сожалению, мы позволить себе не могли, так как это заняло бы слишком много времени.
Чтобы проверять датасет глобально, мы сами размечали по 185 примеров с каждого блока параллельно основной разметке. Перфекционистов сейчас щелкнуло: почему не 200? Это артефакт от схемы проверки, которая в итоге не пошла, а менять уже было накладно. После выполнения блока мы сравнивали разметки между собой. Если количество ошибок превышало наперед заданный порог, то мы отсматривали расхождения на предмет спорности разметки. Если после такой проверки количество ошибок все еще превышало порог — такой блок возвращался на доработку.
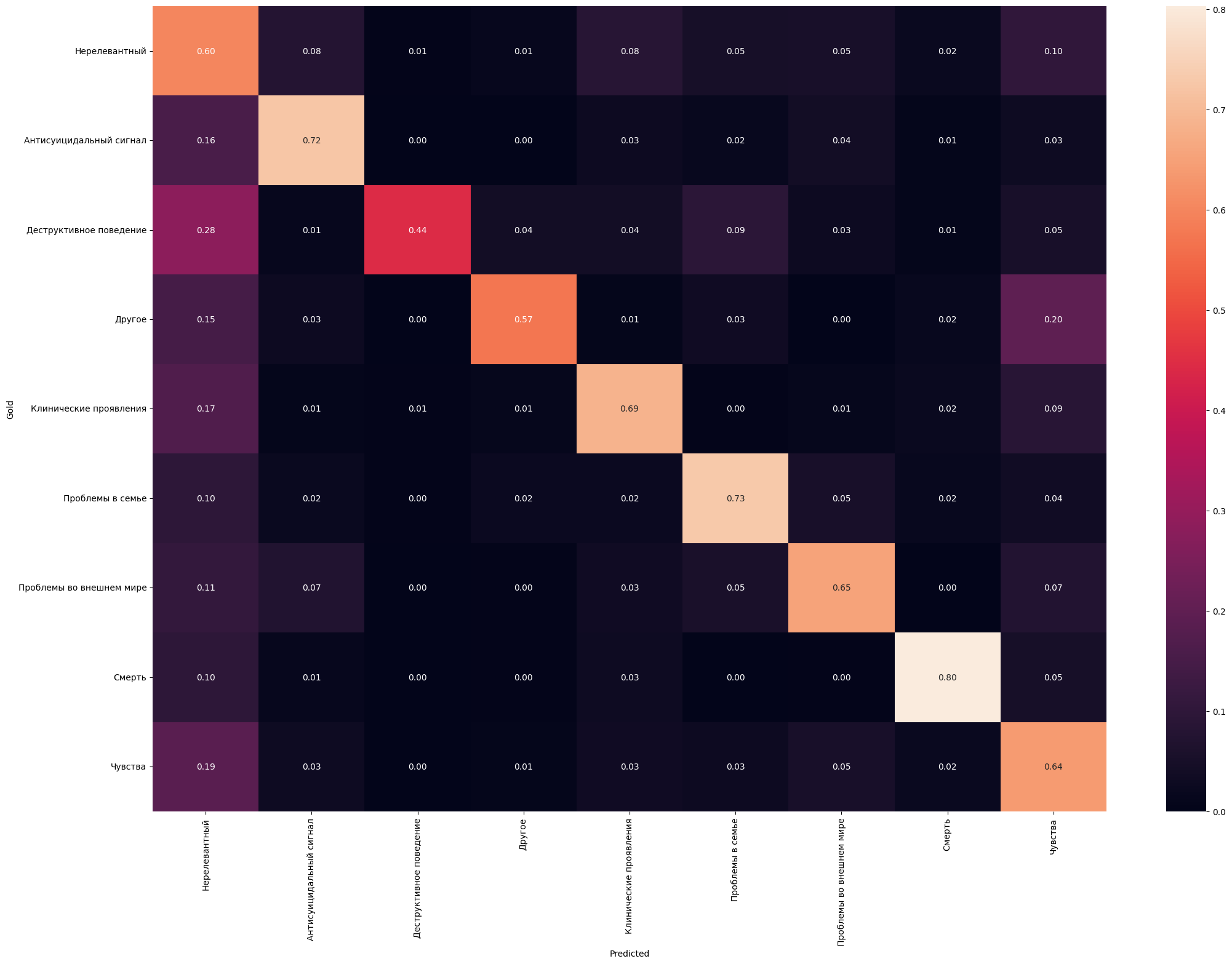
Порог ошибок от числа проверок у нас был 15%. Это число мы сформулировали на основе похожих работ. Если посчитать общий процент ошибок между разметками, то получается, что мы прошли по тонкому льду: для теста мы получили 13,99%, а для трейна — 14,55%. Когда начали обучать модели, выяснилось, что антисуицидальная модель у нас была ужасной по качеству. Мы это ожидали, но не на таком уровне, который увидели. Ожидали потому, что коллеги во время тестовой разметки отмечали, что антисуицидальная часть шла труднее. После анализа ситуации мы решили пересобрать классы для антисуицидальной части и переразметить ее. Как мы это делали, а также как искали ошибки в пресуицидальной части — отдельно писали в нашем девлоге.
Забегая вперед, скажу, что итоговое качество антисуцидальной модели после пересборки классов получилось хуже, чем показали первые тесты из девлога, но существенно лучше, чем исходный вариант.
Что мы получили в итоге
Всего мы собрали 57 810 примеров. Пресуицидальная часть содержит 38 406 примеров, антисуицидальная часть — 9702 примера, нерелевантных примеров тоже получилось 9702 штуки. Согласие между разметчиками по альфе Криппендорфа для пресуицидальный части для теста — 0,542. Чуть больше четверти примеров содержат больше чем один сигнал. В таблицах ниже показано распределение примеров в соответствующих частях.
Распределение в антисуицидальной части
| Имя класса | Кол-во |
|---|---|
| Наличие положительных социальных связей | 1,650 |
| Выражение любви | 1,384 |
| Выражение счастья, радости, удовлетворения | 858 |
| Положительная самооценка | 595 |
| Выражение любви / наличие положительных социальных связей | 486 |
Распределение в пресуицидальной части
| Имя класса | Кол-во |
|---|---|
| Смерть / мысли о смерти | 4,205 |
| Проблемы во внешнем мире / несчастная любовь, проблемы с друзьями, трудности в построении отношений | 3,236 |
| Чувства: беспомощность, безнадежность, отчаяние | 2,602 |
| Чувства: психическая опустошенность, депрессия, тоска, грусть | 2,359 |
Обучение модели и результаты
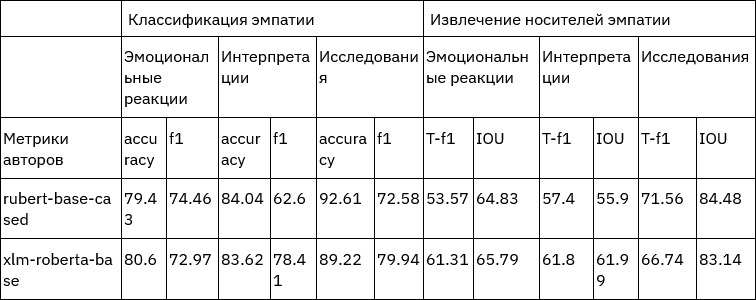
Самое время поговорить о результатах обучения модели — то, к чему мы шли все это время. В качестве базовой мы использовали BERT, поскольку за шесть лет своего существования он стал таким своеобразным Бейзлайном Бейзлайновичем для подобных задач и с ним очень удобно работать. Мы пробовали другие модели типа DeBERTa и RoBERTa, но старый добрый ruBERT показывал лучшие результаты.
В базовом варианте, который отправился в научную статью, мы сделали минимальный препроцессинг: привели тексты к нижнему регистру и убрали любые некириллические символы. Мы также отфильтровали классы, которые имели меньше ста примеров, и убрали тексты с несколькими классами. Структура классов позволяет нам строить модели на разных уровнях гранулярности (детализации):
- точная — используем все классы, которые есть;
- групповая — используем только группы;
- бинарная — есть ли сигнал или нет;
- тернарная — есть ли антисуицидальный или пресуицидальный сигнал.
Вот такие результаты мы получили.
| Тип модели | Гранулярность | Кол-во классов | Точность | Полнота | F1-мера (макро) |
|---|---|---|---|---|---|
| Presuicidal | Group | 8 | 0.65 | 0.65 | 0.65 |
| Presuicidal | Exact | 26 | 0.61 | 0.51 | 0.53 |
| Antisuicidal | Exact | 9 | 0.70 | 0.59 | 0.63 |
| All | Binary | 2 | 0.71 | 0.71 | 0.71 |
| All | Ternary | 3 | 0.71 | 0.69 | 0.70 |
Кстати, наша формальная цель — 70 пунктов по F1-макро для обеих моделей, в которых от трех до семи классов. Чтобы ее достичь, мы немного поколдовали над структурой классов, а кроме того, выбросили некоторые примеры из трейна, которые были шумными. Под колдовством имеется в виду объединение каких-то классов в один как на уровне группы, так и между собой. Например, мы решили оставить классы чувств как группу, потому что, пожалуй, это самый сложный для модели класс. Классы «мысли о смерти» и «намерения о смерти» было решено объединить в один, потому что второй оказался малочисленным и модель не могла уловить его суть. При этом класс этот очень важен, мы не могли его выбросить.
В итоге смогли подобрать конфигурацию, когда мы имеем наибольшее число классов при заданном пороге по F1 в 70 пунктов. Для пресуицидальной модели получилось 15 классов, для антисуицидальной — 10. Надо сказать, что каждая модель также включает в себя класс антагониста, то есть пресуицидальная модель может определить антисуицидальный сигнал, а антисуицидальная — наоборот.
О нашей платформе
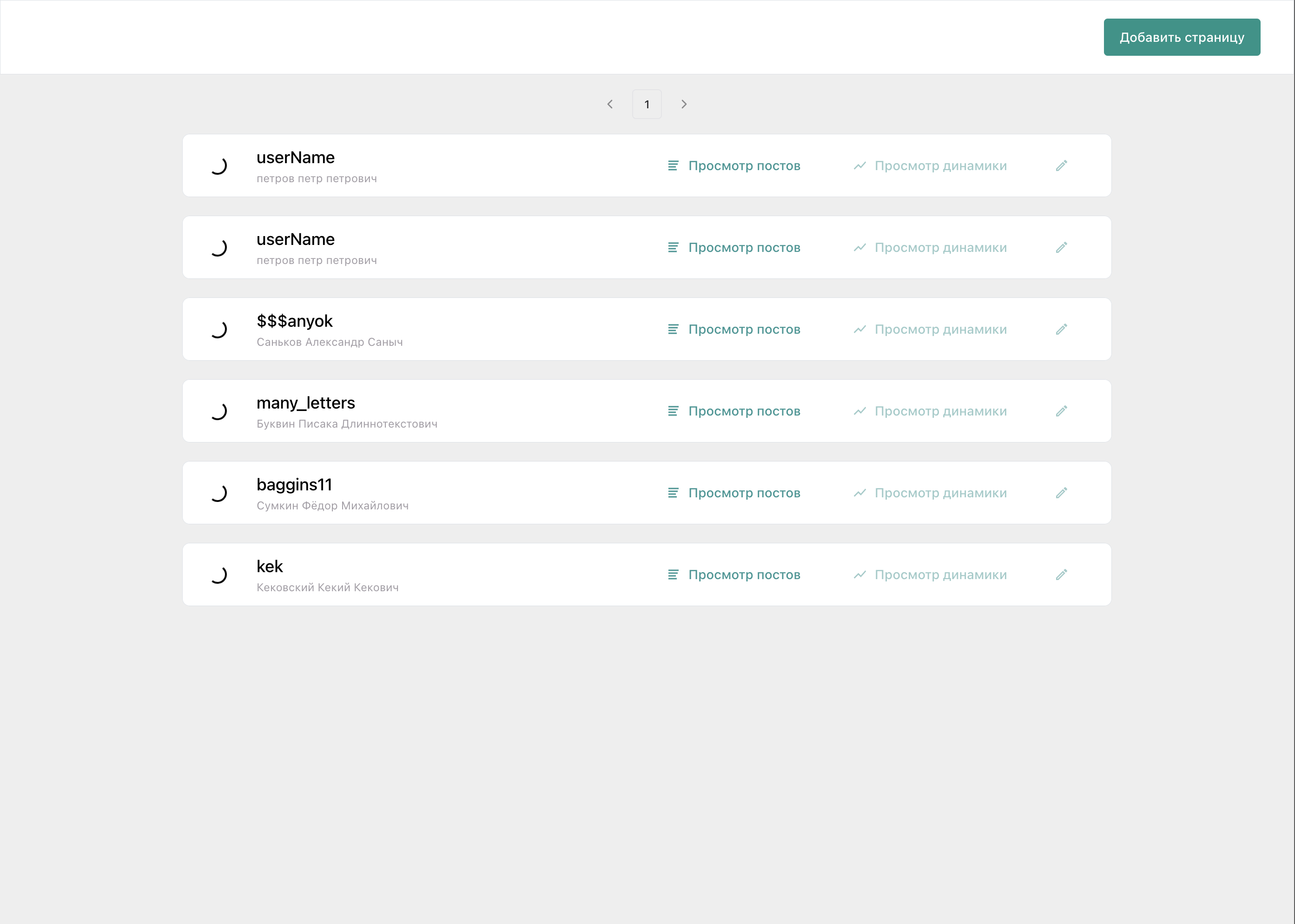
Мало разработать модели. Надо еще сделать так, чтобы люди могли их использовать. Для этого мы разработали платформу «Китобой» с прицелом на анализ текстов пользователей. Она выступает как посредник между волонтерами и моделями. В нее можно загрузить посты, а платформа на каждый пост соберет все предсказания. По умолчанию к ней подключены пресуицидальная и антисуицидальная модели, но могут быть подключены любые другие. Вот как выглядит интерфейс просмотра постов с предсказаниями:
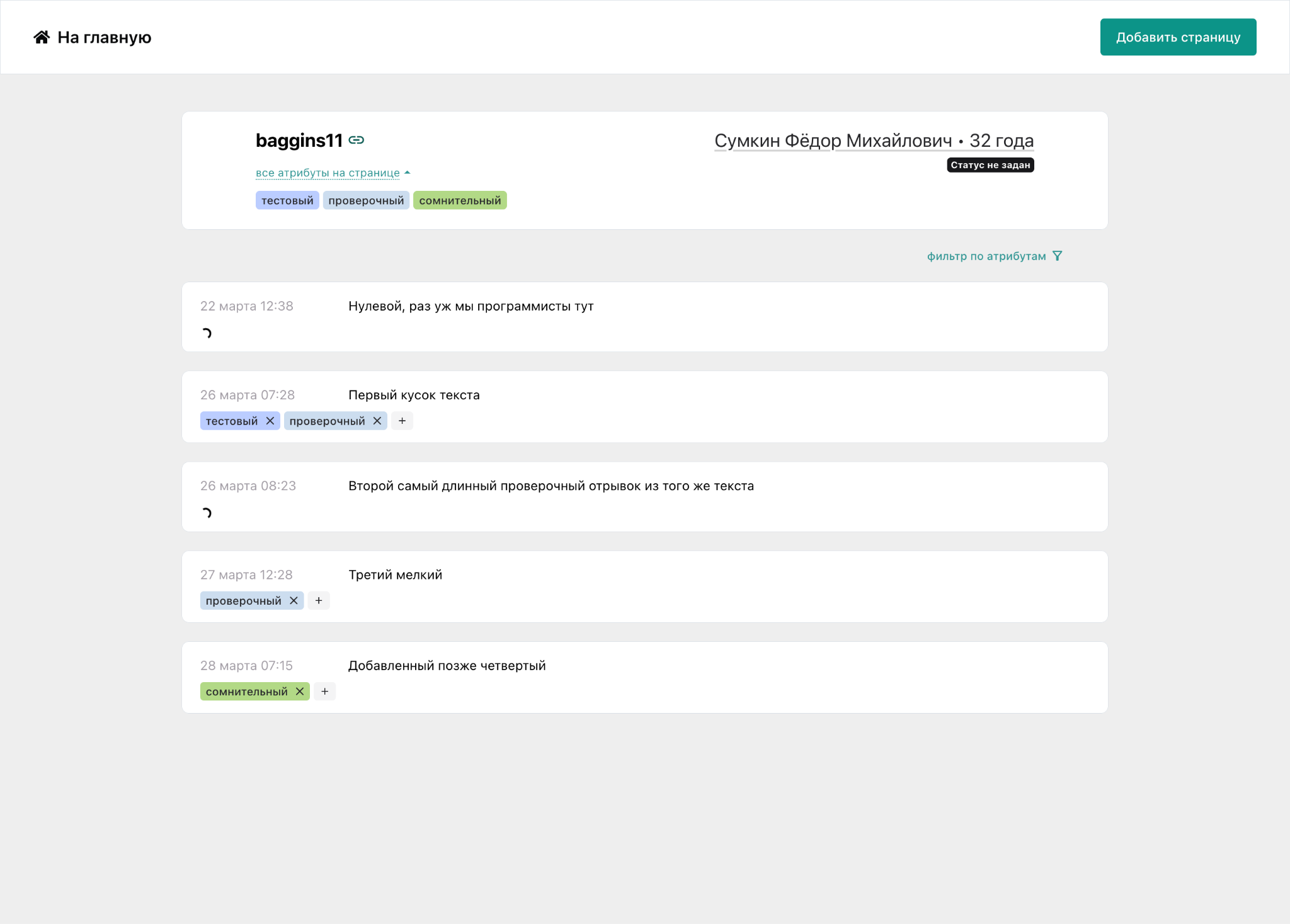
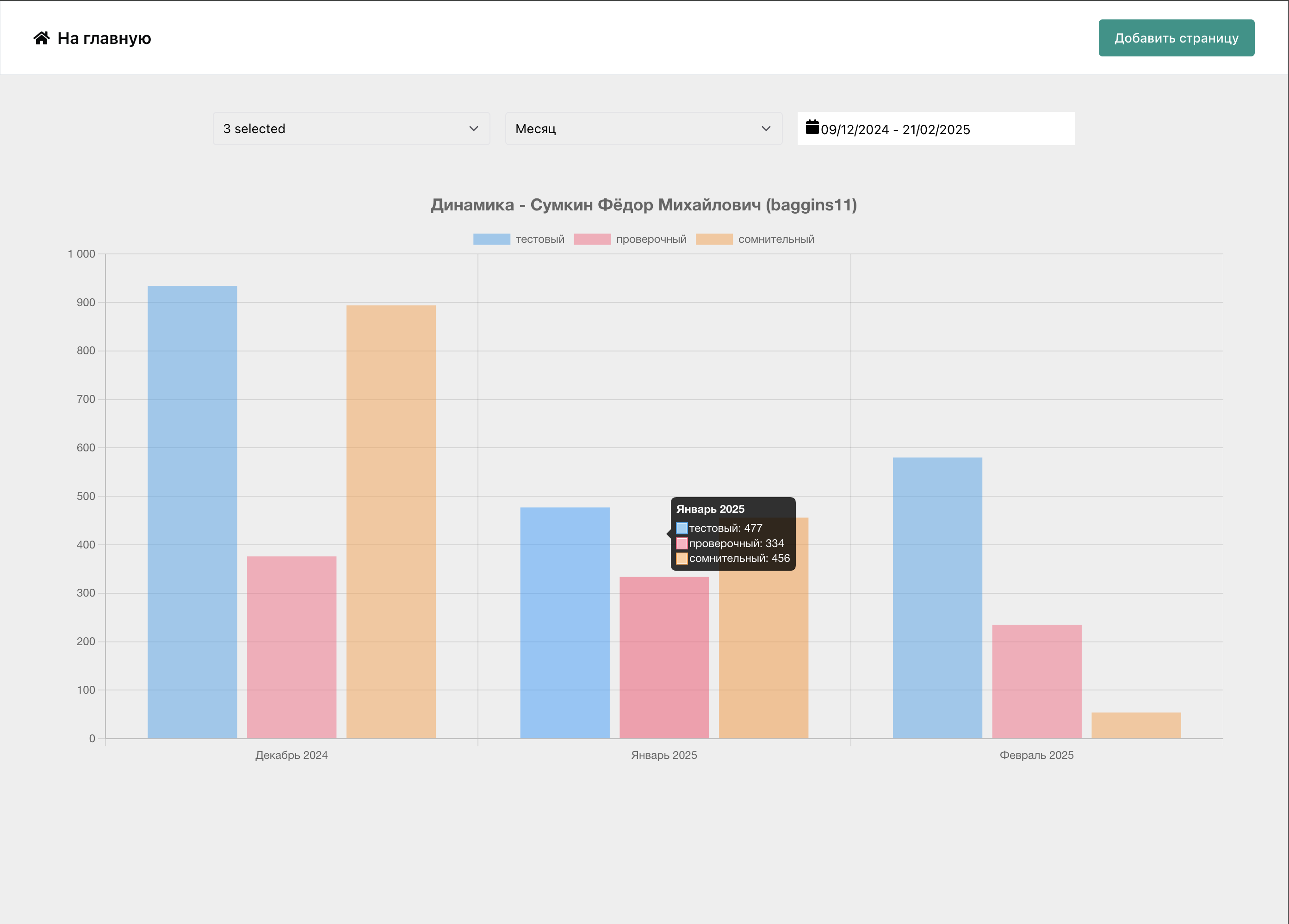
Кроме формата «ленты» постов, вы можете посмотреть на временной график предсказаний, чтобы оценить тренды в настроении и состоянии пользователей, — особая фича нашей платформы. Пример интерфейса:
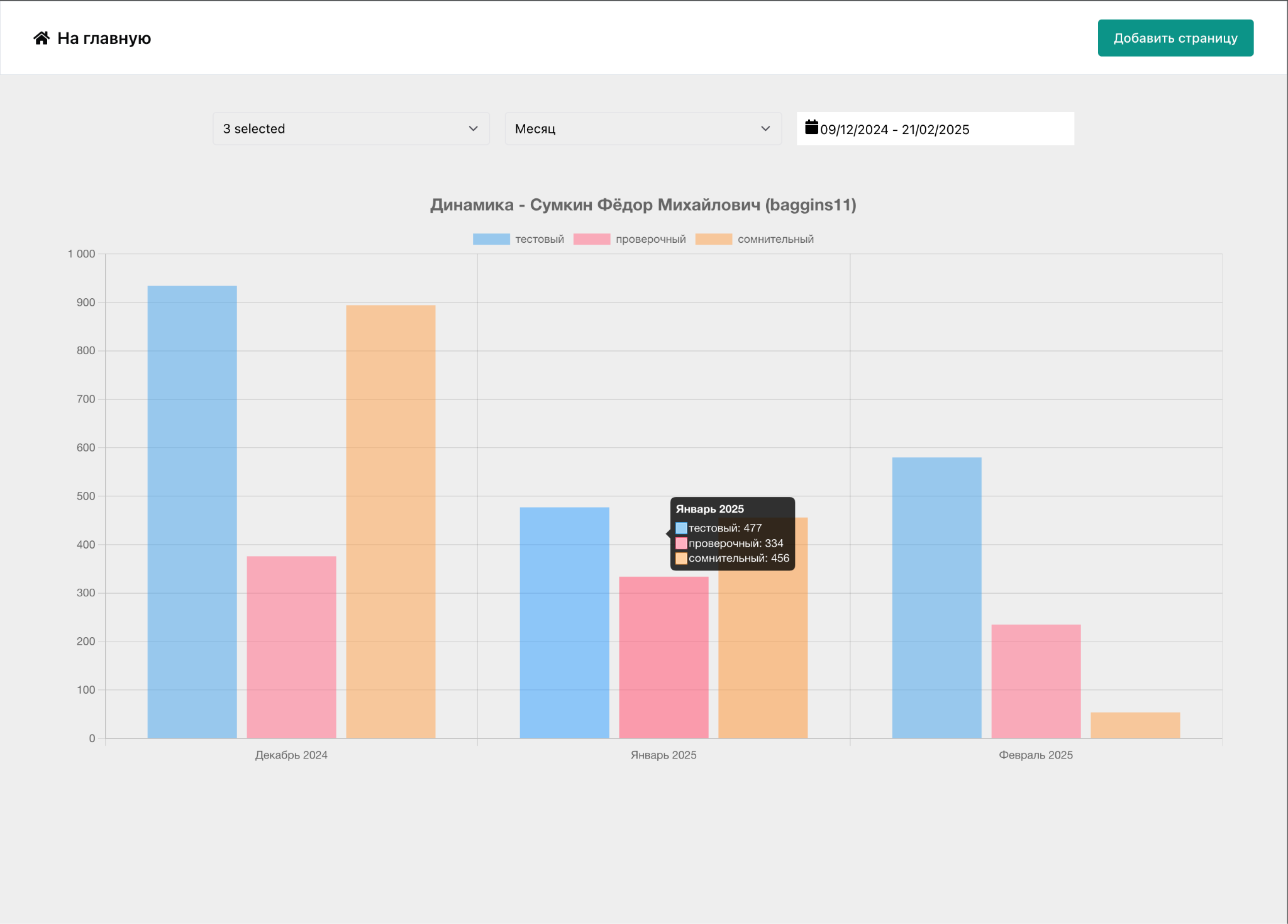
Платформа открытая и вы можете попробовать ее здесь: https://github.com/psytechlab/kitoboy. Там же найдете ссылки на смежные репозитории, модели и датасеты — будем благодарны, если оцените :)
Планы на будущее
После анализа ошибок моделей у нас еще осталось несколько неприятных вещей, которые надо исправить в датасете. Да и вообще хочется значение альфы Криппендорфа >0,7. Для этого надо как-то улучшить методологию разметки, не сводя ее к длиннющему списку корнер-кейсов.
Также, чтобы идти в ногу со временем, мы хотим подключить в процесс LLM. У нас есть две идеи:
- Использовать LLM для суммаризации текстов, которые были определены как какие-либо сигналы.
- Научить LLM определять суицидальные статусы с объяснением. Учитывая, что сейчас модели рассуждают из коробки, это сделать несложно.
- Включить LLM в процесс разметки.
С точки зрения платформы у нас тоже есть идеи, куда расти и что делать:
- Сделать сервис парсинга социальных сетей. Сейчас данные нужно загружать из csv.
- Реализовать записки наблюдателя, куда волонтер может записывать какие-то выводы. Также это интерфейс для функций LLM выше.
- Добавить ролевую систему пользователей платформы с разграничением доступов. В теории должно быть минимум две роли: волонтер, который выполняет анализ пользователя, и супервизор, который проверяет и оценивает самих волонтеров.
Хотим сказать спасибо всем, кто принял участие в разметке данных: Жанна Насхулиян, Анастасия Тюкаева, Артем Загидулин, Ирина Хмелева, Леонид Фомин, Алина Рябушева, Наталья Матвеева, Татьяна Солошенко, Денис Мартынов, Наталья Солошенко.
Давайте сделаем этот мир чуточку лучше.
]]>